
همه ما گاهی اوقات حقیقت را کمی اغراق می کنیم.1 مشکل واقعی زمانی است که دروغ های ما، با کمک پیشرفت های اخیر فناوری مانند رسانه های اجتماعی یا هوش مصنوعی، به سرعت در میان هزاران نفر منتشر می شوند.2, 3 این امر تأثیر قابل توجهی بر تصمیمات افراد دارد؛ از انتخاب فرد مورد نظر برای رأی دادن گرفته تا تصمیم گیری در مورد دریافت واکسن.4, 5, 6
احتمالاً شما قبلاً با این پدیده آشنا هستید: اطلاعات نادرست؛ انتشار اطلاعات غلط یا گمراه کننده.4, 5, 6
در تحقیقات اخیرمان در "دِسیژن لب"، انواع مختلف اطلاعات نادرست را شناسایی و طبقه بندی کردیم و این طبقه بندی را "فیلترینگ روایت های بالقوه نادرست" (SPIN) نامیدیم. امیدواریم این ابزار بتواند به افراد و سازمان ها در مقابله با اطلاعات نادرست و اتخاذ بهترین تصمیمات ممکن کمک کند.
طبقهبندی اطلاعات نادرست چیست؟
طبقهبندی (Taxonomy) سیستمی است برای دستهبندی بر اساس دستورالعملهای مشخص. به طور خاص، طبقهبندیهای اطلاعات نادرست تلاش میکنند به دو هدف دست یابند:
- فهرستبندی همه انواع مرتبط با اطلاعات نادرست
- سازماندهی اطلاعات نادرست بر اساس معیارهای مشخص
هدف نهایی این طبقهبندیها، هدایت مداخلات آتی برای آموزش شرکتکنندگان در شناسایی و در نتیجه مقابله با اطلاعات نادرست است.
اکثر طبقهبندیهای اطلاعات نادرست در گذشته متناسب با حوزههای خاصی مانند آموزش یا سیاست طراحی شدهاند تا راهکارهایی ایجاد کنند که مستقیماً مشکلات موجود در آن زمینه را برطرف کنند.7, 8, 9, 10, 11 در مقابل، هدف ما این بود که طبقهبندی ما شامل هر چه بیشتر انواع مختلف اطلاعات نادرست موجود باشد. به این ترتیب، میتوانیم تعیین کنیم که کدام مداخلات در برخی شرایط موثر هستند و در برخی دیگر موثر نیستند.
ساخت یک طبقهبندی
پس از بررسی ادبیات موجود، لیستی اولیه از انواع اطلاعات نادرست را از دو تا از جامعترین طبقهبندیهایی که توانستیم پیدا کنیم، گردآوری کردیم: طبقهبندیهای کاپانتای و همکاران و کوزیرووا و همکاران. اگرچه در ابتدا هر دو مقاله اصطلاحاتی را که برای زمینههای مورد بررسی آنها نامرتبط بودند حذف کرده بودند، ما تصمیم گرفتیم این اصطلاحات را دوباره اضافه کنیم تا لیست ما تا حد ممکن جامع باشد. سپس، برای پر کردن شکافهای احتمالی، از مدل زبانی بزرگ ML-GPT استفاده کردیم که در نهایت به 63 اصطلاح رسیدیم.
سپس، 12 اصطلاح را بر اساس سه قانون زیر حذف کردیم (به همراه مثالهایی از نحوه اعمال آنها):
- حذف اصطلاحاتی که توسط اصطلاحات گستردهتر دیگری پوشش داده میشوند. به عنوان مثال، اصطلاح "سایت خبری بسیار جانبدارانه" را حذف کردیم زیرا قبلاً توسط اصطلاح "جانبدارانه/یکطرفه" پوشش داده میشد.
- حذف اصطلاحاتی که محتوای اطلاعات را توصیف نمیکنند. به عنوان مثال، اصطلاح "تندروی" را از لیست خود حذف کردیم زیرا نشان نمیدهد چه چیزی به اشتراک گذاشته میشود، بلکه فقط نحوه اشتراکگذاری آن را نشان میدهد.
- ترکیب اصطلاحات مشابه به یک اصطلاح واحد، با حفظ عنوان متداولتر. اصطلاحات "انتخاب گزینشی" و "سوگیری در انتخاب واقعیت" را به "انتخاب گزینشی" خلاصه کردیم زیرا این اصطلاح متداولتر است.
این کار منجر به لیستی نهایی با 51 اصطلاح شد که در زیر مشاهده میکنید.
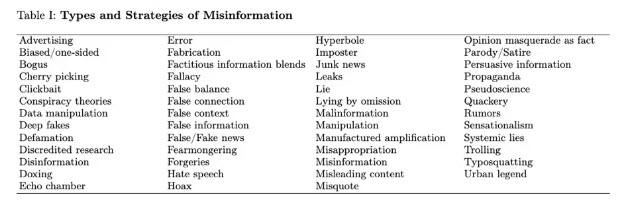
پس از تهیه لیست، زمان آن فرا رسید که آنها را سازماندهی کنیم. از ابتدا، میخواستیم دستههایی ایجاد کنیم که برای اطلاعرسانی به مداخلات آتی بیشترین کمک را ارائه دهند. به عنوان مثال، اگر بخواهیم مداخلهای طراحی کنیم که شرکتکنندگان را تشویق کند تا صحت یک واقعیت را بررسی کنند، ابتدا دانستن اینکه هر نوع اطلاعات نادرست تا چه اندازه "قابل تأیید" است، اهمیت دارد.
به چه نتیجهای رسیدیم؟
به سه دسته گستردهتر رسیدیم: روانشناختی، محتوا و منبع، که هر کدام دارای سه زیرمجموعه هستند.
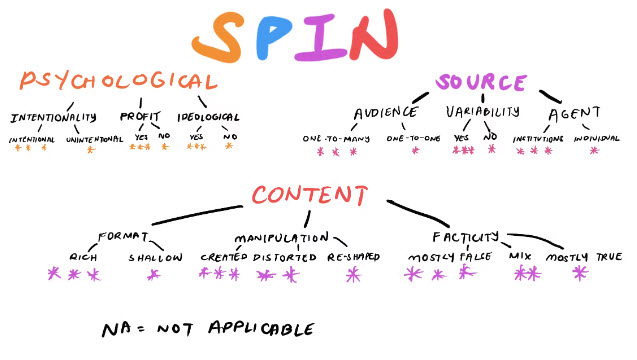
سپس، ما هر یک از 51 نوع اطلاعات خود را در این زیربعدها مرتب کردیم. این همان چیزی است که پنج نفر اول لیست ما به نظر می رسید. (حتما طبقه بندی کامل را اینجا ببینید!)
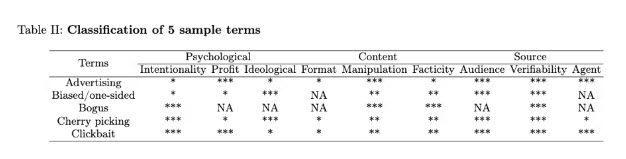
برای درک بهتر این دستهها و زیرمجموعهها، اجازه دهید به بررسی دقیقتر یک ردیف در جدول بپردازیم: طعمه کلیک یا عناوین گمراهکنندهای که برای تشویق کاربران به کلیک کردن روی یک لینک طراحی شدهاند.
روانشناختی
این دسته به انگیزه فرد برای به اشتراکگذاری اطلاعات میپردازد - از جمله افکار، احساسات و نگرشهای او. سه بعد روانشناختی که ما انتخاب کردیم عبارت بودند از: عمدی بودن، سود و ایدئولوژیک.
- عمدی بودن: آیا فرد عمداً دروغ میگوید؟ اصطلاحات میتوانند به عنوان عمدی یا غیرعمدی طبقهبندی شوند. از آنجایی که طعمه کلیک عمداً اغراقآمیز است تا شما را به کلیک کردن بر روی آن ترغیب کند، آن را به عنوان عمدی طبقهبندی کردیم.
- سود: آیا فرد برای کسب درآمد این اطلاعات را به اشتراک میگذارد؟ اصطلاحات میتوانند به عنوان بله یا خیر طبقهبندی شوند. وبسایتهای خبری از طعمه کلیک برای افزایش ترافیک و در نتیجه کسب درآمد استفاده میکنند، که ما این اصطلاح را به عنوان بله طبقهبندی کردیم.
- ایدئولوژیک: آیا فرد با انگیزههای سیاسی یا ارزشهای شخصی این اطلاعات را به اشتراک میگذارد؟ اصطلاحات میتوانند به عنوان بله یا خیر طبقهبندی شوند. اگرچه طعمه کلیک ممکن است از نظرات بحثبرانگیز برای جلب توجه شما استفاده کند، اما انگیزه اصلی همیشه سیاسی نیست، بنابراین ما این اصطلاح را به عنوان خیر طبقهبندی کردیم.
محتوا
این دسته به ویژگیهای محتوای به اشتراک گذاشته شده میپردازد. سه بعد مبتنی بر محتوا که ما انتخاب کردیم عبارت بودند از: قالب، دستکاری و واقعنمایی.
- قالب: چه مقدار اطلاعات ارائه میشود؟ اصطلاحات میتوانند به عنوان غنی یا سطحی طبقهبندی شوند. از آنجایی که طعمه کلیک فقط شامل عنوان یا تصویر کوچک یک مقاله یا ویدیو است، آن را به عنوان سطحی طبقهبندی کردیم.
- دستکاری: فرد چگونه محتوا را دستکاری میکند؟ اصطلاحات میتوانند به عنوان ساخته شده، تحریف شده یا بازنشر شده طبقهبندی شوند. طعمه کلیک نه از ابتدا ساخته میشود و نه صرفاً "بازنشر" میشود. در عوض، نهادها معمولاً داستانی را پیچ و تاب میدهند، بنابراین ما این اصطلاح را به عنوان تحریف شده طبقهبندی کردیم.
- واقعنمایی: چقدر احتمال دارد که این اظهارات درست باشند؟ اصطلاحات میتوانند به عنوان غیر واقعی، عمدتاً واقعی یا مختلط طبقهبندی شوند. از آنجایی که طعمه کلیک جنبههای واقعی یک داستان را با جزئیات اغراقآمیز یا حتی ساختگی ترکیب میکند، ما این اصطلاح را به عنوان مختلط طبقهبندی کردیم.
منبع
این دسته بازیگران اصلی را توصیف میکند، از جمله افرادی که اطلاعات را به اشتراک میگذارند و افرادی که آن را دریافت میکنند. سه بعد مبتنی بر منبع که ما انتخاب کردیم عبارت بودند از: مخاطب، قابل تأیید بودن و عامل.
- مخاطب: مخاطب چقدر گسترده است؟ اصطلاحات میتوانند به عنوان یک به چند یا یک به یک طبقهبندی شوند. مقالات و ویدیوها در اینترنت با هزاران بیننده بالقوه به اشتراک گذاشته میشوند، بنابراین ما طعمه کلیک را به عنوان یک به چند طبقهبندی کردیم.
- قابل تأیید بودن: آیا میتوان به سرعت و به راحتی بررسی کرد که این اظهارنظر چقدر درست است؟ اصطلاحات میتوانند به عنوان بله یا خیر طبقهبندی شوند. پس از کلیک کردن روی مقاله یا ویدیو، معمولاً کاملاً واضح است که این مقاله یا ویدیو به صورت آزادانه بر اساس واقعیت است. با توجه به این موضوع، ما طعمه کلیک را به عنوان بله طبقهبندی کردیم.
- عامل: اطلاعات از کجا میآید؟ اصطلاحات میتوانند به عنوان نهادها یا افراد طبقهبندی شوند. از آنجایی که طعمه کلیک معمولاً توسط یک سازمان منتشر میشود، ما عامل را به عنوان نهادها شناسایی کردیم.
هر زمان که یک بعد برای یک اصطلاح خاص قابل اجرا نبود، پاسخ "NA" یا "قابل اجرا نیست" را انتخاب کردیم.
پس چه؟
چه چیزهایی خوب پیش رفت؟
ما به هدف اصلی خود که ایجاد لیستی جامع از انواع اطلاعات نادرست یا گمراه کننده بود، دست یافتیم. این کار با گنجاندن طیف گستردهای از اصطلاحات در چندین بخش، بر محدودیتهای طبقهبندیهای قبلی غلبه کرد. به عنوان مثال، "تحقیقات بیاعتبار" ممکن است اصطلاحی مرتبطتر با محیط دانشگاهی باشد، در حالی که "اخبار جعلی" ممکن است پیامدهای سیاسی بیشتری داشته باشد. ما همچنین منابع سنتی اطلاعات نادرست مانند "افسانههای شهری" را در نظر گرفتیم و در عین حال منابع جدیدی را از پیشرفتهای تکنولوژیکی مانند "دیپفیک" نیز در نظر گرفتیم.
چه مواردی نیاز به کار دارند؟
البته، این بدان معنا نیست که طبقهبندی ما کامل است. واقعیت ناخوشایند این است که به دلیل حجم زیاد کلمات، امکان گنجاندن هر نوع اطلاعات نادرست وجود نداشت. همچنین شایان ذکر است که هر اصطلاحی که ما در نظر گرفتیم، دارای طیف گستردهای از تعاریف و مثالها است. این امر طبقهبندی اصطلاحات گستردهتر مانند "جعلی"، "اطلاعات نادرست" یا "دستکاری" را که موارد مختلف آن حتی ممکن است با یکدیگر در تضاد باشند، دشوار کرد. با این حال، این مشکل خاص تحقیقات ما نیست، بلکه ذاتی هر طبقهبندی اطلاعات نادرست است و بهروزرسانی و اصلاح مداوم آن را حتی مهمتر میکند.
از اینجا به کجا برویم؟
همانطور که قبلاً نیز گفتیم، هدف نهایی این طبقهبندی، کمک به طراحی مداخلات آتی برای کمک به شرکتکنندگان در شناسایی انواع اطلاعات نادرست است. این میتواند شامل مداخلات قبلی مانند بازی خبر بد که به شرکتکنندگان نحوه تشخیص اخبار جعلی را آموزش میدهد، و همچنین طراحی مداخلات جدید برای مقابله مستقیم با انواع خاصی از اطلاعات نادرست باشد.
تا آن زمان، امیدواریم این طبقهبندی را تا حد ممکن در دسترس قرار دهیم تا هر کسی بتواند از آن به عنوان ابزاری برای شناسایی اطلاعات نادرست استفاده کند. به این ترتیب، همه ما میتوانیم شروع به اتخاذ تصمیمات آگاهانهتر در زندگی خود کنیم.
آیا شما به مبارزه با اطلاعات نادرست از طریق علوم رفتاری علاقهمند هستید؟ The Decision Lab مشتاق همکاری با محققان و متخصصان برای توسعه و اصلاح بیشتر مداخلات با استفاده از طبقهبندی SPIN ما است. برای کمک به ما در ماموریت خود برای ایجاد دنیایی آگاهانهتر، امروز با ما تماس بگیرید!
منابع:
- Sai, L., Shang, S., Tay, C., Liu, X., Sheng, T., Fu, G., ... & Lee, K. (2021). Theory of mind, executive function, and lying in children: a meta‐analysis. Developmental Science, 24(5), e13096.
- Kaiser, J., & Rauchfleisch, A. (2018). Unite the right? How YouTube’s recommendation algorithm connects the US far-right. D&S Media Manipulation.
- Tufekci, Z. (2018). YouTube, the great radicalizer. The New York Times, 10(3), 2018.Van der Linden, S., Leiserowitz, A., Rosenthal, S., & Maibach, E. (2017). Inoculating the public against misinformation about climate change. Global challenges, 1(2), 1600008.
- Lewandowsky, S., Ecker, U. K., Seifert, C. M., Schwarz, N., & Cook, J. (2012). Misinformation and its correction: Continued influence and successful debiasing. Psychological science in the public interest, 13(3), 106-131.
- Shao, C., Ciampaglia, G. L., Varol, O., Yang, K. C., Flammini, A., & Menczer, F. (2018). The spread of low-credibility content by social bots. Nature communications, 9(1), 1-9.
- Vosoughi, S., Roy, D., & Aral, S. (2018). The spread of true and false news online. science, 359(6380), 1146-1151.
- Kapantai, E., Christopoulou, A., Berberidis, C., & Peristeras, V. (2021). A systematic literature review on disinformation: Toward a unified taxonomical framework. New media & society, 23(5), 1301-1326.
- Kozyreva, A., Lewandowsky, S., & Hertwig, R. (2020). Citizens versus the internet: Confronting digital challenges with cognitive tools. Psychological Science in the Public Interest, 21(3), 103-156.
- Molina M, Sundar S, Le T, et al. (2019) “Fake news” is not simply false information: a concept explication and taxonomy of online content. American Behavioral Scientist. Epub ahead of print 14 October. DOI: 10.1177/0002764219878224.
- Rojecki, A., & Meraz, S. (2016). Rumors and factitious informational blends: The role of the web in speculative politics. New Media & Society, 18(1), 25-43.
- Wardle, C., & Derakhshan, H. (2017). Information disorder: Toward an interdisciplinary framework for research and policymaking (Vol. 27, pp. 1-107). Strasbourg: Council of Europe.
- Roozenbeek, J. (2019). Fake news game confers psychological resistance against online misinformation. Palgrave Communications, 5(1), 1-10. https://doi.org/10.1057/s41599-019-0279-9
دیدگاه خود را بنویسید