
سوگیری نمایندگی چیست؟
شباهت در واقع یک روش سادهسازی ذهنی است که ما برای تخمین احتمالها از آن استفاده میکنیم. به جای اینکه به طور دقیق اعداد و آمار را بررسی کنیم، اغلب سعی میکنیم رویداد مورد نظر را با نمونههای ذهنی مشابه مقایسه کنیم. اگر این رویداد به نمونههای ذهنی ما شبیهتر باشد، احتمال وقوع آن را بیشتر میدانیم.
سوگیری نمایندگی یک روش ذهنی سریع است که ما برای تخمین احتمالها از آن استفاده میکنیم. وقتی میخواهیم احتمال وقوع یک رویداد را ارزیابی کنیم، اغلب تصمیم خود را با ارزیابی میزان شباهت آن به یک نمونه ذهنی موجود میگیریم.
به عبارت دیگر، ما احتمال را بر اساس شباهت رویداد به یک نمونه ذهنی تخمین میزنیم، نه بر اساس آمار واقعی.
این روش ذهنی میتواند منجر به قضاوتهای نادرست شود، زیرا ممکن است شباهت لزوماً با احتمال وقوع مرتبط نباشد.

جایی که این سوگیری رخ میدهد
فرض کنید میخواهید با دوستتان سارا به کنسرتی بروید. او دو دوست خود به نامهای جان و آدم را هم دعوت کرده که شما قبلاً آنها را ندیدهاید. شما میدانید که یکی ریاضیدان است و دیگری موسیقیدان.
وقتی در نهایت با دوستان سارا ملاقات میکنید، متوجه میشوید که جان عینک زده و کمی خجالتی است، در حالی که آدم برعکس او، برونگراتر است و تیشرت گروه موسیقی و شلوار جین پاره پوشیده است. بدون پرسیدن، شما حدس میزنید که جان باید ریاضیدان باشد و آدم باید موسیقیدان باشد. بعداً متوجه میشوید که اشتباه کردهاید: آدم ریاضی میخواند و جان موسیقی مینوازد.
به دلیل سوگیری نمایندگی، شما شغل آدم و جان را بر اساس کلیشههایی در مورد نحوه لباس پوشیدن این مشاغل حدس زدید. این اتکا باعث شد تا شما نشانههای بهتر برای تشخیص حرفه آنها، مانند سؤال ساده از آنها در مورد کارشان، را نادیده بگیرید.
اثرات فردی
از آنجا که ما تمایل داریم به نمایندگی اعتماد کنیم، اغلب از در نظر گرفتن انواع دیگر اطلاعات غفلت میکنیم که منجر به پیشبینیهای ضعیف میشود. سوگیری نمایندگی آنقدر فراگیر است که بسیاری از پژوهشگران معتقدند این سوگیری پایه و اساس چندین سوگیری دیگر است که پردازش ما را تحت تأثیر قرار میدهد، از جمله خطای ترکیب و خطای قمارباز.
خطای ترکیب زمانی رخ میدهد که ما فرض کنیم چندین چیز بیشتر از یک چیز به تنهایی احتمال وقوع دارند. از نظر آماری، این هرگز درست نیست، اما سوگیری نمایندگی ممکن است ما را متقاعد کند.
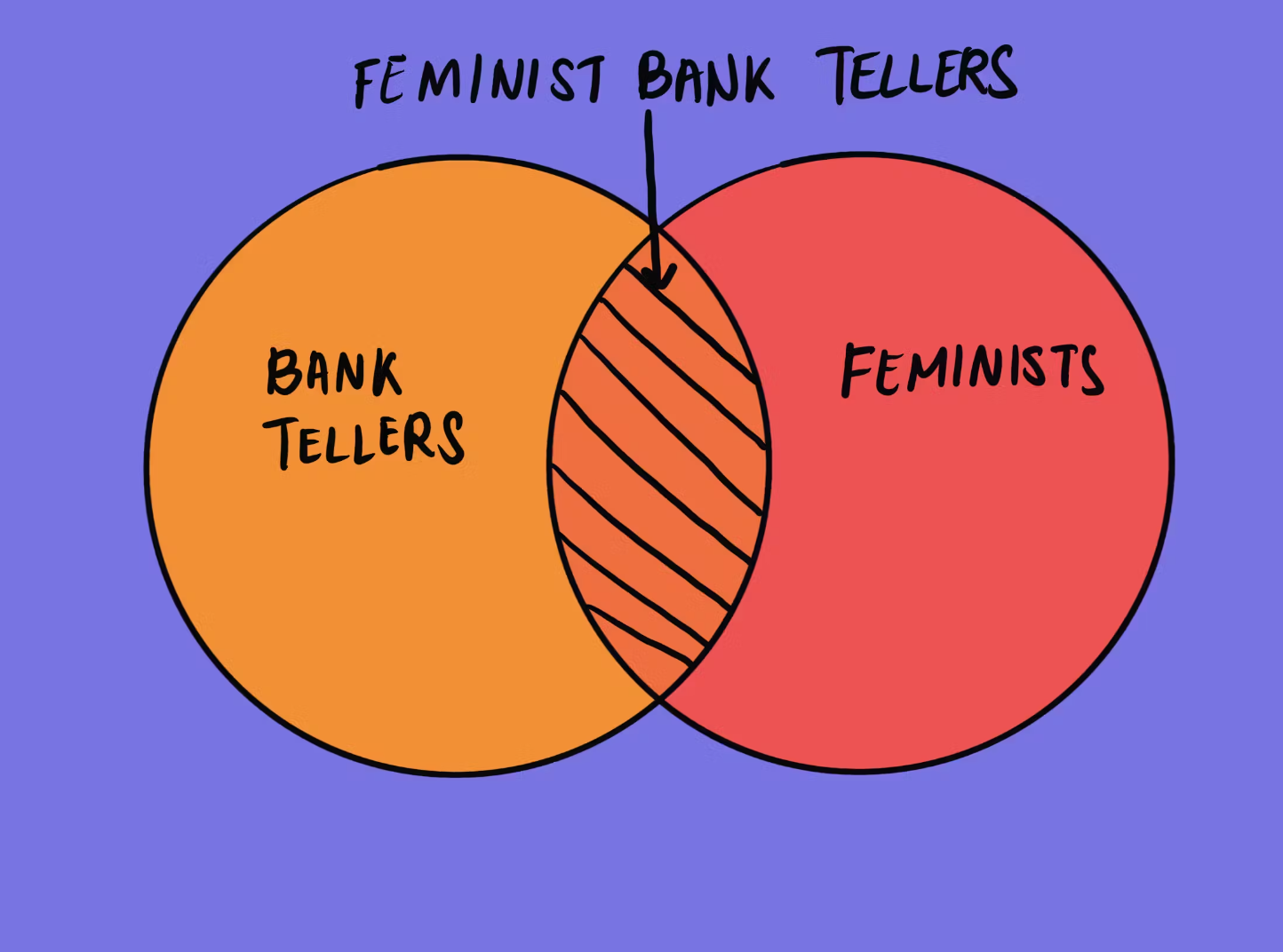
لیزا را در نظر بگیرید که یک فارغالتحصیل فلسفه درخشان است و به شدت نگران تبعیض و عدالت اجتماعی است. وقتی گزینه داده میشود، ما بسیار بیشتر احتمال میدهیم حدس بزنیم که او هم یک فمینیست فعال است و هم یک صندوقدار بانکی، نه فقط یک صندوقدار بانکی. این به دلیل نمایندگی است: این واقعیت که لیدا شبیه یک فمینیست نمونه است، توانایی ما را در پیشبینی احتمال شغل او منحرف میکند.
سوگیری دیگری که ناشی از سوگیری نمایندگی است، سوگیری قمارباز است که باعث میشود مردم احتمالهای بلندمدت را به توالیهای کوتاهمدت اعمال کنند.
برای مثال، در پرتاب سکه، تقریباً شانس پنجاه-پنجاه برای گرفتن شیر یا خط وجود دارد. این به این معنی نیست که اگر یک سکه را دو بار پرتاب کنید، یک بار شیر و یک بار خط خواهید آورد. احتمال فقط در توالیهای طولانی، مانند پرتاب یک سکه صد بار، کار میکند. با این حال، ما معتقدیم که احتمال کوتاهمدت باید نماینده همتایان بلندمدت خود باشد، حتی اگر این تقریباً هرگز اتفاق نیفتد.
همانطور که از نام آن پیداست، سوگیری قمارباز میتواند عواقب جدی برای قماربازان داشته باشد. به عنوان مثال، ممکن است کسی باور کند که شانس برنده شدن او بهتر است اگر در یک سری باخت کوتاه بوده است، حتی اگر رسیدن به آن احتمال به چندین بار باخت بیشتر نیاز داشته باشد.
اثرات سیستماتیک
اعتماد ما به دستهها میتواند به راحتی به تعصب تبدیل شود، حتی اگر متوجه آن نباشیم. نحوه نمایش گروههای اقلیت توسط رسانههای جمعی اغلب کلیشههای رایج را تقویت میکند. به عنوان مثال، مردان سیاهپوست در پوشش جرم و فقر بیش از حد نشان داده میشوند، در حالی که به عنوان کارشناسان "سر صحبت" کمنمایندگی میشوند. این الگوها از روایتی حمایت میکنند که مردان سیاهپوست خشونتآمیز هستند، که حتی بینندگان سیاهپوست ممکن است آن را درونی کنند و در طبقهبندی خود بگنجانند.
این کلیشهها از سوگیری نمایندگی به تبعیض سیستماتیک کمک میکنند. به عنوان مثال، پلیسهایی که به دنبال یک مظنون جرم هستند ممکن است به طور نامتناسب روی افراد سیاهپوست در جستجوی خود تمرکز کنند. تعصبات آنها باعث میشود که آنها فرض کنند یک فرد سیاهپوست بیشتر از کسی از گروه دیگری احتمال دارد که مجرم باشد.
چگونه بر محصول تأثیر میگذارد
نمایندگی یک ابزار ارزشمند برای توسعه رابط کاربری (UI) است. طراحان دیجیتال به طور عمدی نمادهایی را برای نشان دادن دستهها گنجاندهاند تا ما را هنگام حرکت در فضاهای مجازی راهنمایی کنند، اغلب بدون اینکه حتی متوجه شویم.
به عنوان مثال، وقتی نماد سطل زباله را میبینیم، میدانیم که میتوانیم اسناد خود را برای دور ریختن روی آن بکشیم، درست مانند اینکه اسناد کاغذی را در دنیای واقعی دور میاندازیم. یا وقتی نماد دیسک فلاپی را میبینیم، میدانیم که میتوانیم روی آن کلیک کنیم تا سند خود را ذخیره کنیم، درست مانند زمانی که اطلاعات را ذخیره میکردیم. این نمونههای اولیه یادآوری خوبی هستند که چگونه مواد میتوانند در هنگام طراحی محصولات جدید به درک بهتر ما از دیجیتال کمک کنند.
سوگیری نمایندگی و هوش مصنوعی
یادگیری ماشینی با تکیه بر الگوهای آماری و نرخ پایه برای دسته بندی اطلاعات بهینه شده است. با این حال، انسانها هنوز در هنگام تفسیر این خروجیها به سوگیری نمایندگی مبتلا هستند.
به عنوان مثال، سیستم مراقبت بهداشتی از فناوری هوش مصنوعی برای کمک به تشخیص بیماران با اسکن تصاویر پزشکی و مقایسه آنها با هزاران تصویر دیگر در مجموعه داده خود استفاده کرده است. پزشکان ممکن است در صورتی که علائم با توصیف نمونهای از یک بیماری مطابقت داشته باشد، بیشتر به تشخیص هوش مصنوعی اعتماد کنند. با این حال، پزشکان ممکن است تشخیصهای هوش مصنوعی را در صورتی که با این الگوها همخوانی نداشته باشد، رد کنند، حتی اگر هوش مصنوعی دسترسی بسیار بیشتری به ارائههای نادر یا غیرمعمول علائم در فایلهای خود نسبت به پزشکان داشته باشد.
چرا این اتفاق میافتد
سوگیری نمایندگی توسط دنیل کانمن و آموس تفسری، دو چهره تأثیرگذار در اقتصاد رفتاری، ابداع شد. مثال کلاسیکی که آنها برای نشان دادن این سوگیری استفاده کردند، از خواننده میخواهد استیو را در نظر بگیرد: دوستانش او را "بسیار خجالتی و گوشهگیر، همیشه کمککننده، اما با علاقه کمی به مردم یا دنیای واقعی" توصیف میکنند. او روحی آرام و مرتب دارد، به نظم و ساختار نیاز دارد و به جزئیات علاقهمند است." بعد از خواندن این توصیف، فکر میکنید استیو کتابدار است یا کشاورز؟
بیشتر ما به طور شهودی احساس میکنیم که استیو باید کتابدار باشد زیرا او بیشتر نماینده تصویر ما از یک کتابدار نسبت به تصویر ما از یک کشاورز است. در واقع، هیچ مدرکی مستقیماً به حرفه استیو اشاره نمیکند، بنابراین ما برای تصمیمگیری به کلیشهها تکیه میکنیم.
صرفهجویی در انرژی با دستهها
مانند همه سوگیریها، دلیل اصلی تکیه ما بر نمایندگی این است که ما منابع ذهنی محدودی داریم. از آنجایی که ما روزانه هزاران تصمیم میگیریم، مغز ما برای صرفهجویی در انرژی تا حد امکان سیمکشی شده است. این بدان معناست که ما اغلب برای قضاوت سریع در مورد دنیای اطراف خود به میانبرها متکی هستیم. با این حال، دلیل دیگری برای وقوع سوگیری نمایندگی وجود دارد که ریشه در نحوه درک ما از مردم و اشیاء دارد.
ما برای تصمیمگیری از نمونههای اولیه استفاده میکنیم
گروه بندی چیزهای مشابه با هم، یعنی طبقهبندی آنها، بخش ضروری از نحوه درک ما از جهان است. این ممکن است بدیهی به نظر برسد، اما دستهها اساسیتر از چیزی هستند که بسیاری از مردم تصور میکنند. به تمام چیزهایی که در یک روز با آنها روبرو میشوید فکر کنید. هر زمان که با انسانها، حیوانات یا اشیاء تعامل میکنیم، از دانشی که در مورد آن دسته یاد گرفتهایم استفاده میکنیم تا بدانیم چه کاری باید انجام دهیم.
برای مثال، وقتی به پارک سگها میروید، ممکن است حیواناتی را در طیف وسیعی از شکلها، اندازهها و رنگها ببینید. اما از آنجایی که میتوانید همه آنها را به عنوان "سگ" طبقهبندی کنید، بلافاصله میدانید که چه انتظاری دارید: آنها میدوند و چیزهایی را تعقیب میکنند، مانند گرفتن جایزه، و اگر یکی از آنها شروع به غرغر کرد، احتمالاً باید عقبنشینی کنید.
بدون دستهها، هر بار که با چیزی جدید روبرو میشدیم، باید از ابتدا یاد میگرفتیم که چیست و چگونه کار میکند. چه برسد به اینکه ذخیره کردن اطلاعات بسیار زیاد در مورد هر موجودیت جداگانه با توجه به ظرفیت شناختی محدود ما غیرممکن خواهد بود. به همین دلیل، توانایی ما در درک و یادآوری چیزها در مورد جهان به طبقهبندی بستگی دارد.
از سوی دیگر، نحوه یادگیری اولیه ما برای طبقهبندی چیزها نیز میتواند بر نحوه درک ما از آنها تأثیر بگذارد. به عنوان مثال، در روسی، سایههای روشنتر و تیره تر آبی نامهای متفاوتی دارند ("goluboy" و "siniy")، در حالی که در انگلیسی، ما به هر دو "آبی" میگوییم. تحقیقات نشان میدهد که این تفاوت در طبقهبندی بر نحوه درک واقعی مردم از رنگ آبی تأثیر میگذارد: روسزبانان در مقایسه با انگلیسیزبانان سریعتر بین آبی روشن و تیره تمایز قائل میشوند.
بر اساس یکی از فرضیههای طبقهبندی به نام نظریه نمونه اولیه، ما از آمار ذهنی ناخودآگاه برای تشخیص اینکه یک عضو "متوسط" از یک دسته چگونه به نظر میرسد استفاده میکنیم. وقتی میخواهیم در مورد چیزها یا افراد ناآشنا تصمیمگیری کنیم، به این میانگین - نمونه اولیه - به عنوان یک نمونه نماینده از کل دسته مراجعه میکنیم. شواهد جالبی وجود دارد که از این ایده حمایت میکند که انسانها به نوعی میتوانند اعضای "متوسط" دسته را به این شکل محاسبه کنند. به عنوان مثال، مردم تمایل دارند صورتهایی را جذابتر پیدا کنند که به "صورت متوسط" تولید شده توسط رایانه نزدیکتر باشند.
نمونههای اولیه تخمینهای ما را در مورد احتمال هدایت میکنند، درست مانند مثالی که ما حرفه استیو را حدس زدیم. نمونه اولیه ما برای کتابداران احتمالاً کسی است که بسیار شبیه استیو است - خجالتی، مرتب و عینکی - در حالی که نمونه اولیه ما برای کشاورزان احتمالاً کسی است که عضلانیتر، زمینیتر و کمروتر است. به طور شهودی، ما احساس میکنیم که استیو باید کتابدار باشد زیرا ما مجبوریم به لحاظ دستهها و میانگینها فکر کنیم.
ما اهمیت شباهت را بیش از حد ارزیابی میکنیم
مشکل سوگیری نمایندگی این است که در واقع هیچ ارتباطی با احتمال ندارد، اما با این حال، ما ارزش بیشتری نسبت به اطلاعات مرتبط به آن میدهیم. یک نوع از این اطلاعات نرخ پایه است: آمار نشاندهندهی فراوانی چیزی در جمعیت عمومی. برای مثال، در ایالات متحده کشاورزان بسیار بیشتر از کتابداران هستند. این بدان معناست که از نظر آماری، این اشتباه است که بگوییم استیو "احتمال بیشتری" دارد که کتابدار باشد، صرف نظر از اینکه شخصیت او چگونه است یا چگونه خودش را نشان میدهد.
اندازه نمونه نوع دیگری از اطلاعات مفید است که اغلب آن را نادیده میگیریم. هنگام تخمین یک جمعیت بزرگ بر اساس یک نمونه، میخواهیم نمونه ما تا حد امکان بزرگ باشد تا تصویر کاملتری به ما بدهد. اما وقتی بیش از حد روی نمایندگی تمرکز میکنیم، اندازه نمونه میتواند نادیده گرفته شود.
برای نشان دادن این موضوع، تصور کنید یک شیشه پر از توپ است. ⅔ توپها یک رنگ هستند، در حالی که ⅓ رنگ دیگری دارند. سالی پنج توپ از شیشه بیرون میکشد که چهار تای آن قرمز و یکی سفید است. جیمز ۲۰ توپ میکشد که ۱۲ تای آن قرمز و هشت تای آن سفید است. بین سالی و جیمز، چه کسی باید مطمئنتر باشد که توپهای داخل شیشه ⅔ قرمز و ⅓ سفید هستند؟
بیشتر مردم میگویند سالی شانس بیشتری برای درست بودن دارد زیرا نسبت توپهای قرمز کشیده شده توسط او بیشتر از نسبت توپهای قرمز کشیده شده توسط جیمز است. اما این درست نیست: جیمز نمونهی بزرگتری از توپها نسبت به سالی کشیده است، بنابراین او در موقعیت بهتری برای قضاوت در مورد محتویات شیشه است. ما وسوسه میشویم که نمونهی ۴:۱ سالی را انتخاب کنیم زیرا نمایندهتر از نسبت مورد نظر ما نسبت به ۱۲:۸ جیمز است، اما این منجر به خطا در قضاوت ما میشود.
چرا مهم است
نمایندگی برای شناسایی و تفسیر ضروری است. به این ترتیب، میتوانیم چیزی کاملاً جدید را بدون شروع از صفر درک کنیم. گاهی اوقات، این چیز جدید در درون خودمان وجود دارد. برای مثال، هنگام کشف جنسیت یا هویت جنسی خود، ممکن است راحتتر باشد که با یک برچسب جدید برای درک آنچه که تجربه میکنیم، خود را شناسایی کنیم. در مواقع دیگر، این چیز جدید در دیگران وجود دارد. به عنوان مثال، اگر برادر شما به عنوان همجنسگرا ظاهر شود، ممکن است برای درک بهتر تجربه او به آنچه که در مورد دوستان همجنسگرای خود میدانیم تکیه کنیم.
با این حال، دو مشکل در تکیه صرف بر طبقهبندی دقیق وجود دارد.
اول، ممکن است در نظر گرفتن منحصر به فرد بودن را فراموش کنیم. باور کنید یا نه، ما میتوانیم کاملاً خارج از دستهها قرار بگیریم، درست مانند افراد غیر دوتایی که احساس نمیکنند جنسیت آنها تحت هیچ برچسب دقیقی قرار میگیرد. در چنین شرایطی، تحمیل کردن دستهها بر کسی ممکن است او را بیشتر از آنچه که واقعاً هست دور کند، تا اینکه به خودشناسی کمک کند.
دوم، بسیاری از دستهها دارای ارتباطات نادرست هستند. بسیاری از گروهها به ویژه در مورد اقلیتها مانند LGBTQ+ با کلیشهها آزار میبینند. این بدان معناست که به محض اینکه بفهمیم یک فرد به کدام دسته تعلق دارد، ممکن است بیشتر از حد معمول در مورد آنها فرضیههای اشتباه بگیریم.
از آنجایی که سوگیری نمایندگی ما را تشویق میکند تا منحصر به فرد بودن را نادیده بگیریم و به ارتباطات نادرست باور کنیم، باید یاد بگیریم که هنگام پیشبینی بیش از حد به دستهها اعتماد نکنیم.
چگونه از آن اجتناب کنیم
از آنجایی که طبقهبندی برای درک ما از جهان بسیار اساسی است، اجتناب کامل از سوگیری نمایندگی غیرممکن است. با این حال، آگاهی یک شروع خوب است. تحقیقات بیشماری نشان میدهد که وقتی مردم متوجه میشوند که از یک روش سادهسازی استفاده میکنند، اغلب قضاوت اولیه خود را اصلاح میکنند. اشاره کردن به اتکای دیگران به نمایندگی و درخواست از آنها برای انجام همین کار برای شما، بازخورد مفیدی ارائه میدهد که ممکن است به جلوگیری از این سوگیری کمک کند.
پژوهشگران دیگر سعی کردهاند با تشویق مردم به "فکر کردن مانند آماردانان" اثرات سوگیری نمایندگی را کاهش دهند. این تذکرها به نظر میرسد مفید هستند، اما مشکل این است که بدون یک نشانه واضح، مردم فراموش میکنند از دانش آماری خود استفاده کنند، حتی کسانی که در دانشگاه هستند.
یک استراتژی دیگر با پایداری بالقوه بیشتر، آموزش رسمی در تفکر منطقی است. در یک مطالعه، کودکانی که برای تفکر منطقیتر آموزش دیده بودند، بیشتر احتمال داشت از خطای ترکیب اجتناب کنند. با این ذهنیت، یادگیری بیشتر در مورد آمار و تفکر انتقادی ممکن است به ما در جلوگیری از سوگیری نمایندگی کمک کند.
چگونه همه چیز شروع شد
در حالی که طبقهبندی یک پایه اصلی در روانشناسی مدرن است، مرتبسازی اشیاء را میتوان تا فیلسوفان یونان باستان ردیابی کرد. در حالی که افلاطون برای اولین بار در گفتگوی «سیاستمدار» خود به دستهها اشاره کرد، این موضوع به یک موضوع اصلی فلسفی برای شاگردش، ارسطو تبدیل شد. ارسطو در کتاب خود با عنوان دقیق «دستهها»، هدف داشت هر شیء قابل درک انسانی را در یکی از ده دسته مرتب کند.
نظریه نمونه اولیه توسط روانشناس النور راش در سال 1974 معرفی شد. تا آن زمان، دستهها به صورت همه یا هیچ در نظر گرفته میشدند: چیزی یا به یک دسته تعلق داشت یا نداشت. رویکرد راش تشخیص داد که اعضای یک دسته اغلب از یکدیگر بسیار متفاوت به نظر میرسند و ما تمایل داریم برخی چیزها را به عنوان اعضای «بهتر» یک دسته در نظر بگیریم. به عنوان مثال، وقتی به دسته پرندگان فکر میکنیم، پنگوئنها به اندازه مثلاً یک گنجشک به خوبی در این گروه جای نمیگیرند. ایده نمونههای اولیه به ما اجازه میدهد توصیف کنیم که چگونه برخی از اعضای دسته را در مقایسه با دیگران بهعنوان نمایندهتر از دسته خود درک میکنیم.
تقریباً در همان زمان، کانمن و تفسری مفهوم سوگیری نمایندگی را به عنوان بخشی از تحقیقات خود در مورد استراتژیهایی که مردم برای تخمین احتمال در شرایط نامشخص استفاده میکنند، معرفی کردند. کانمن و تفسری نقش پیشگامانهای در اقتصاد رفتاری داشتند و نشان دادند که مردم به دلیل تکیه بر استراتژیهای مغرضانه، از جمله سوگیری نمایندگی، دچار خطاهای سیستماتیک در قضاوت میشوند.
مثال ۱ - نمایندگی و زخم معده
زخم معده یک بیماری نسبتاً شایع است، اما اگر درمان نشود میتواند جدی شود و حتی گاهی منجر به سرطان معده کشنده شود. برای مدت طولانی، این دانش رایج بود که زخم معده توسط یک چیز ایجاد میشود: استرس. بنابراین در دهه ۱۹۸۰، زمانی که یک پزشک استرالیایی به نام باری مارشال در یک کنفرانس پزشکی پیشنهاد کرد که نوعی باکتری ممکن است باعث زخم شود، همکارانش در ابتدا آن را رد کردند. پس از نادیده گرفته شدن، مارشال سرانجام با استفاده از تنها روش اخلاقی در دسترس خود، سوء ظن خود را ثابت کرد: او مقداری از باکتری روده یک بیمار بیمار را برداشت، به آن آب گوشت اضافه کرد و خودش آن را خورد. او به زودی دچار زخم معده شد و پزشکان دیگر در نهایت متقاعد شدند.
چرا اینقدر طول کشید (و چنین اقدام افراطی) تا دیگران را از این احتمال جدید متقاعد کنیم؟ طبق گفته روانشناسان اجتماعی توماس گیلویچ و کنت ساویتسکی، پاسخ سوگیری نمایندگی است. احساسات فیزیکی که مردم از زخم معده تجربه میکنند - دردهای سوزنده و معدهای که میچرخد - شبیه به چیزی است که هنگام تجربه استرس احساس میکنیم. در سطح شهودی، احساس میکنیم که زخمها و استرس باید ارتباطی با هم داشته باشند. به عبارت دیگر، استرس یک علت نماینده زخم است. این ممکن است دلیل مقاومت سایر متخصصان پزشکی در برابر پیشنهاد مارشال بوده باشد.
مثال ۲ - نمایندگی و طالع بینی
گیلویچ و ساویتسکی همچنین استدلال میکنند که سوگیری نمایندگی در باورهای شبهعلمی از جمله طالع بینی نقش دارد. در طالع بینی، هر علامت زودیاک با ویژگیهای خاصی مرتبط است. به عنوان مثال، برج حمل، یک «علامت آتش» که با قوچ نمادین شده است، اغلب گفته میشود که پرشور، مطمئن، بیصبر و پرخاشگر است. این واقعیت که این توصیف با قوچ نمونهای به خوبی مطابقت دارد تصادفی نیست: انواع شخصیت مرتبط با هر علامت ستاره به این دلیل انتخاب شدهاند که نماینده آن علامت هستند. پیشبینیهایی که طالعبینی انجام میدهد، به جای پیشبینی آینده، بر اساس آنچه بیشتر با تصویر ما از هر علامت مطابقت دارد، مهندسی معکوس میشوند.
دیدگاه خود را بنویسید